
Summer 2023
It’s a long summer, and AI has been a buzz ever since Chat GPT was introduced to the general public. Since then it’s been a roller coaster ride of AI advancements, and the latest one is GPT-4. While there is much heated debate on whether it’s out to replace us or turn into a skynet version of virtual overlords, I wanted to see if it’s any good at writing tech blogs.
I tend to post when excitement or curiosity strikes, and I’m not the most consistent blogger. So I figured if GPT can give me reasonable enough content with a guiding but firm hand, I can get back to writing more often.
The Experiment
Given a set of topics/themes is GPT able to write a blog post that is coherent and relevant? Can it make jokes? or does it write everything in a robotic tone? Can it link images to the post, better yet even reference them.
I had high hopes for GPT-4, so I fired up Chat GPT’s chat window and asked away. It started out writing jokes a 5 year old would be proud of, but I persisted and it started to get better™.
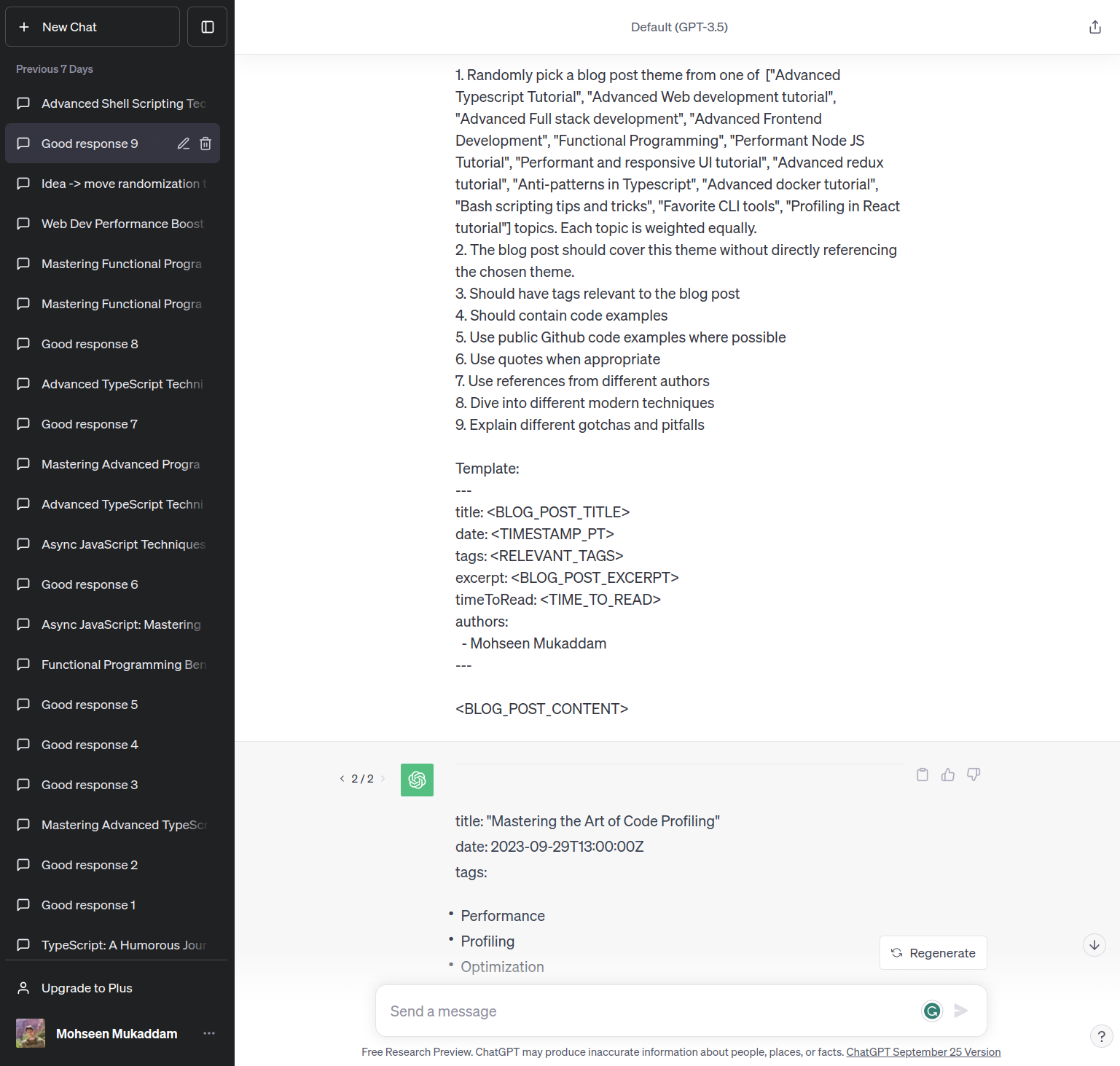
I asked it to write in different styles for different topics, and it was able to do so with varying degrees of success. The most clunky part was the image linking, it would link to images that did not exists, ever, yet it believed them to be true with all its heart.
After fine tuning my prompts and refining some of the asks that I made to GPT-3.5, it eventually looked like something I would be okay with posting (sometimes).
Next, I had to see if it would write a blog post in markdown the way my flavor of Hugo likes it. This was a bit tricky but after reading through a dozen or so responses, I figured some scripting magic might help my cause.
Building the Pipeline
For building this automated CRON job, I needed a few things:
- A way to trigger the job
- Fetch content from GPT-4
- Validate and fetch images (since GPT-3.5/4 really wasn’t good at this)
- Build the website
- Transport it to the webs
CRON does meet these requirements but would require a lot of heavy lifting on my end. My goal was to be as lazy as possible, so I opted for Apache Airflow. A dockerized version of Airflow with all Pythonic and Bashy goodness was all I needed to get started.
Repo for this project is available here
Airflow lets you define DAGs (Directed Acyclic Graphs) which are essentially a set of tasks that are executed in a specific order. It also allows fine grained control on how/what triggers them, how to handle outputs from different operators, build in retries, catchup and a lot more.
After installing dependencies, I needed to get it Dockerized and running on my local machine. I used the official docker-compose file to get started.
version: "3.8"
x-airflow-common: &airflow-common
# In order to add custom dependencies or upgrade provider packages you can use your extended image.
# Comment the image line, place your Dockerfile in the directory where you placed the docker-compose.yaml
# and uncomment the "build" line below, Then run `docker-compose build` to build the images.
# image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.7.1}
build: .
environment: &airflow-common-env
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
# For backward compatibility, with Airflow <2.3
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__BROKER_URL: redis://:@redis:6379/0
AIRFLOW__CORE__FERNET_KEY: ""
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: "true"
AIRFLOW__CORE__LOAD_EXAMPLES: "true"
AIRFLOW__API__AUTH_BACKENDS: "airflow.api.auth.backend.basic_auth,airflow.api.auth.backend.session"
# yamllint disable rule:line-length
# Use simple http server on scheduler for health checks
# See https://airflow.apache.org/docs/apache-airflow/stable/administration-and-deployment/logging-monitoring/check-health.html#scheduler-health-check-server
# yamllint enable rule:line-length
AIRFLOW__SCHEDULER__ENABLE_HEALTH_CHECK: "true"
AIRFLOW_VAR_GITHUB_TOKEN: ${GITHUB_TOKEN:-}
AIRFLOW_VAR_GITHUB_USER: ${GITHUB_USER:-}
AIRFLOW_VAR_GITHUB_REPOSITORY: ${GITHUB_REPOSITORY:-}
AIRFLOW_VAR_OPENAI_API_KEY: ${OPENAI_API_KEY:-}
AIRFLOW_VAR_GITHUB_WEBSITE_REPOSITORY: ${GITHUB_WEBSITE_REPOSITORY:-}
AIRFLOW_VAR_UNSPLASH_TOKEN: ${UNSPLASH_TOKEN:-}
AIRFLOW_VAR_SENDGRID_API_KEY: ${SENDGRID_API_KEY:-}
AIRFLOW_VAR_SENDGRID_SUCCESS_TEMPLATE: ${SENDGRID_SUCCESS_TEMPLATE:-}
AIRFLOW_VAR_SENDGRID_FAILURE_TEMPLATE: ${SENDGRID_FAILURE_TEMPLATE:-}
AIRFLOW__CORE__HIDE_SENSITIVE_VAR_CONN_FIELDS: ${AIRFLOW__CORE__HIDE_SENSITIVE_VAR_CONN_FIELDS:-'true'}
# WARNING: Use _PIP_ADDITIONAL_REQUIREMENTS option ONLY for a quick checks
# for other purpose (development, test and especially production usage) build/extend Airflow image.
_PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:-}
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags
- ${AIRFLOW_PROJ_DIR:-.}/logs:/opt/airflow/logs
- ${AIRFLOW_PROJ_DIR:-.}/config:/opt/airflow/config
- ${AIRFLOW_PROJ_DIR:-.}/plugins:/opt/airflow/plugins
- ${AIRFLOW_PROJ_DIR:-.}/constants:/opt/airflow/gpt_publisher/constants
user: "${AIRFLOW_UID:-50000}:0"
depends_on: &airflow-common-depends-on
redis:
condition: service_healthy
postgres:
condition: service_healthy
By default Airflow uses a SQLite database, but I wanted to use a more standardized way for running and scheduling tasks. So I opted for Postgres and Redis as the backend and message broker. It truly is wild how many different ways you can set Airflow up. Docker does solve a key problem Portability and Dependency Management.
Once I had Redis and Postgres services defined, all I needed to do was add my flavor of dependencies for fetching, processing and uploading these files to my blog.
services:
postgres:
image: postgres:13
environment:
POSTGRES_USER: airflow
POSTGRES_PASSWORD: airflow
POSTGRES_DB: airflow
volumes:
- postgres-db-volume:/var/lib/postgresql/data
healthcheck:
test: ["CMD", "pg_isready", "-U", "airflow"]
interval: 10s
retries: 5
start_period: 5s
restart: always
redis:
image: redis:latest
expose:
- 6379
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 10s
timeout: 30s
retries: 50
start_period: 30s
restart: always
airflow-webserver:
<<: *airflow-common
command: webserver
ports:
- "8080:8080"
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:8080/health"]
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-scheduler:
<<: *airflow-common
command: scheduler
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:8974/health"]
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
Creating the DAG
Once I had the dependencies sorted, I needed to create a DAG that would do a few key things:
- Pick a random theme for blog post
- Fetch content from GPT-4
- Validate and fetch images from Unsplash
- Process images and remove any unnecessary content
- Build the website
- Upload the website to Github
- Send a notification email on success or failure
- Run this every Friday at 10:00 AM
with DAG(
dag_id="publish_blog_post",
# Once every week on Friday at 10:00 AM UTC
schedule="0 10 * * 5",
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
dagrun_timeout=datetime.timedelta(minutes=60),
tags=["gpt-publisher"],
render_template_as_native_obj=True,
) as dag:
Once you have a dag defined, the scheduler will pick it up and start running it at the specified time. You can also trigger it manually from the UI.
Next, how to inject secrets and tokens to Airflow container. Airflow provide a lot of way to configure this, but the one I found best suited for this was Variables.
You can inject any environment variable from your Docker container into an Airflow variable by prefixing it with AIRFLOW_VAR*. This does store it in the metadata database, so might come with some perf hit when reading, but it was good enough for my use case.
AIRFLOW_VAR_GITHUB_TOKEN: ${GITHUB_TOKEN:-}
AIRFLOW_VAR_GITHUB_USER: ${GITHUB_USER:-}
AIRFLOW_VAR_GITHUB_REPOSITORY: ${GITHUB_REPOSITORY:-}
AIRFLOW_VAR_OPENAI_API_KEY: ${OPENAI_API_KEY:-}
AIRFLOW_VAR_GITHUB_WEBSITE_REPOSITORY: ${GITHUB_WEBSITE_REPOSITORY:-}
AIRFLOW_VAR_UNSPLASH_TOKEN: ${UNSPLASH_TOKEN:-}
AIRFLOW_VAR_SENDGRID_API_KEY: ${SENDGRID_API_KEY:-}
AIRFLOW_VAR_SENDGRID_SUCCESS_TEMPLATE: ${SENDGRID_SUCCESS_TEMPLATE:-}
AIRFLOW_VAR_SENDGRID_FAILURE_TEMPLATE: ${SENDGRID_FAILURE_TEMPLATE:-}
Docker compose picks up any local .env you may have, and inject it for you.
Finally, let’s define the Dockerfile that has extra dependencies we might need to successfully pull this off.
FROM apache/airflow:2.7.1
USER root
RUN apt-get update && apt-get install -y \
git
LABEL authors="momo"
WORKDIR /tmp
RUN curl -L https://go.dev/dl/go1.21.1.linux-amd64.tar.gz > go1.21.1.linux-amd64.tar.gz
RUN rm -rf /usr/local/go && tar -C /usr/local -xzf go1.21.1.linux-amd64.tar.gz
ENV PATH="/usr/local/go/bin:${PATH}"
ENV GOPATH="/usr/local/go"
RUN go version
RUN rm -rf /tmp/go1.21.1.linux-amd64.tar.gz
RUN apt-get install hugo -y
RUN hugo version
# Install package dependencies
USER airflow
WORKDIR /opt/airflow
COPY requirements.txt requirements.txt
COPY setup.py setup.py
RUN pip install --upgrade pip
RUN mkdir -p gpt_publisher
WORKDIR /opt/airflow/gpt_publisher
COPY gpt_publisher/__init__.py __init__.py
WORKDIR /opt/airflow
RUN echo "Installing base package"
RUN pip install -e .
RUN echo "Installing requirements"
RUN pip install -r requirements.txt
Graphing the tasks
Once Airflow is good to go, we now start with defining the tasks that need to be executed in a specific order. Airflow provides a lot of operators out of the box, but you can also create your own custom operators.
First task involves picking a random topic from a predefined list
@task(task_id="pick_topic")
def pick_topic():
length = len(GPT_TOPICS)
index = random.randint(0, length - 1)
return GPT_TOPICS[index]
Pretty straightforward, next we need to send the topic of choice to GPT-4
Fetching Content from GPT-4
I used the OpenAI Python Client client to get chat completions based on my prompts.
@task(task_id="call_gpt")
def call_gpt(ti=None):
"""
Calls ChatGPT 4 to generate a blog post
"""
theme = ti.xcom_pull(task_ids="pick_topic")
assert theme is not None or theme is not ""
prompt = gpt_prompt(theme)
openai_api_key = Variable.get("OPENAI_API_KEY")
assert openai_api_key is not None or openai_api_key is not ""
openai.api_key = openai_api_key
response = openai.ChatCompletion.create(
model="gpt-4", messages=[{"role": "user", "content": prompt}]
)
raw_text = response["choices"][0]["message"]["content"]
assert raw_text is not None or raw_text is not ""
return raw_text
One fascinating wrinkle with Airflow tasks is they need to communicate the results of runs with each other. Airflow solves this with XCom. XCom allows dependent tasks to pull relevant information from the previous task and use it in their own execution. It’s sort of like passing around a context in a request flow
theme = ti.xcom_pull(task_ids="pick_topic")
Once available we can use it and send the GPT-4 response for further processing.
Processing Blog post response
This is where things get a bit tricky, GPT-4 is not perfect and it does make mistakes. So we need to validate the response and make sure it’s good enough to be posted.
@task(task_id="process_blog_post")
def process_blog_post(ti=None):
"""
Processes the blog post, sanitizes date and tags
"""
post = ti.xcom_pull(task_ids="call_gpt")
assert post is not None or post is not ""
date = datetime.datetime.now().isoformat().split("T")[0]
post = re.sub(DATE_TIME_REGEX, f"date: {date}", post)
tags = re.findall(TAGS_REGEX, post)
tags = tags[0].split(",")
tags = [tag.strip() for tag in tags]
tags = [
tag.replace("_", " ").replace("-", " ").replace('"', "").replace("'", "")
for tag in tags
]
raw_title = re.findall(TITLE_REGEX, post)
assert raw_title and len(raw_title) > 0
raw_title = raw_title[0].strip()
title_words = re.findall(WORD_REGEX, raw_title)
assert title_words and len(title_words) > 0
title_words = [word.lower() for word in title_words]
title_words = "-".join(title_words)
file_name = f"{date}-{title_words}.md"
return {
"post": post,
"tags": tags,
"date": date,
"file_name": file_name,
"title": title_words,
}
Fetching Images from Unsplash
After we sanitize the post, we can fetch relevant images from Unsplash and add them to the post.
@task(task_id="fetch_images")
def fetch_images(ti=None):
context = ti.xcom_pull(task_ids="process_blog_post")
tags = context["tags"][:2]
query = ", ".join(tags)
token = Variable.get("UNSPLASH_TOKEN")
assert token is not None or token is not ""
headers = {
"Authorization": f"Client-ID {token}",
}
url = f"{UNSPLASH_BASE_URL}/search/photos"
params = {
"query": query,
}
response = requests.get(url, headers=headers, params=params)
json = response.json()
results = json["results"]
assert results and len(results) > 0
idx = random.randint(0, len(results) - 1)
image_urls = results[idx]["urls"]
preview = image_urls["small"]
desktop = image_urls["full"]
tablet = image_urls["regular"]
mobile = image_urls["small"]
fallback = image_urls["thumb"]
return {
**context,
"preview": preview,
"desktop": desktop,
"tablet": tablet,
"mobile": mobile,
"fallback": fallback,
}
Next up, is preparing the images for downloading them into the blog post.
Processing Images
@task(task_id="process_images")
def process_images(ti=None):
context = ti.xcom_pull(task_ids="fetch_images")
post = context["post"]
title = context["title"]
post = re.sub(PREVIEW_REGEX, f" /images/hero/{title}.preview.jpg", post)
post = re.sub(DESKTOP_REGEX, f" /images/hero/{title}.desktop.jpg", post)
post = re.sub(TABLET_REGEX, f" /images/hero/{title}.tablet.jpg", post)
post = re.sub(MOBILE_REGEX, f" /images/hero/{title}.mobile.jpg", post)
post = re.sub(FALLBACK_REGEX, f" /images/hero/{title}.fallback.jpg", post)
# Weird hack for jinja2 template rendering, that strips out newlines
post = post.replace("\n", "<NEW_LINE_TOKEN>")
return {
**context,
"post": post,
}
Given our template that’s predominantly used in Hugo, we swap in the correct values at run time and make sure the images are available for Hugo to pick up.
Piecing it all together
Lastly, we need to gather all relevant tags, post, images and build the website.
run = BashOperator(
task_id="publish_blog_post",
bash_command="/opt/airflow/dags/scripts/publish.sh ",
env={
"GITHUB_WEBSITE_REPOSITORY": Variable.get("GITHUB_WEBSITE_REPOSITORY"),
"GITHUB_REPOSITORY": Variable.get("GITHUB_REPOSITORY"),
"CLONE_URL": clone_url,
"CLONE_WEBSITE_REPO_URL": website_repo_url,
"BLOG_FILENAME": "{{ ti.xcom_pull(task_ids='process_images')['file_name'] }}",
"BLOG_CONTENT": "{{ ti.xcom_pull(task_ids='process_images')['post'] }}",
"PREVIEW_URL": "{{ ti.xcom_pull(task_ids='process_images')['preview'] }}",
"DESKTOP_URL": "{{ ti.xcom_pull(task_ids='process_images')['desktop'] }}",
"TABLET_URL": "{{ ti.xcom_pull(task_ids='process_images')['tablet'] }}",
"MOBILE_URL": "{{ ti.xcom_pull(task_ids='process_images')['mobile'] }}",
"FALLBACK_URL": "{{ ti.xcom_pull(task_ids='process_images')['fallback'] }}",
"BLOG_TITLE": "{{ ti.xcom_pull(task_ids='process_images')['title'] }}",
},
do_xcom_push=True,
)
I chose the BashOperator because it uses dependencies from the host OS (in our case, the Docker container) to weave together all the pieces from previous runs.
# Reaffirm GO path
export PATH=/usr/local/go/bin:$PATH
echo "Cloning ${GITHUB_REPOSITORY} repo..."
# Weird hack for jinja2 template rendering, that strips out newlines
PARSED_BLOG_CONTENT="${BLOG_CONTENT//<NEW_LINE_TOKEN>/\\n}"
mkdir -p /tmp/gh
cd /tmp/gh || exit 127
rm -rf website-v7
git clone "$CLONE_URL"
cd website-v7 || exit 127
git checkout master
cd content/post || exit 127
echo "Writing to file..."
touch "$BLOG_FILENAME"
echo "$PARSED_BLOG_CONTENT" > "$BLOG_FILENAME"
# Replace \n with actual newlines
awk '{gsub(/\\n/,"\n")}1' "$BLOG_FILENAME" > "$BLOG_FILENAME.tmp" && mv "$BLOG_FILENAME.tmp" "$BLOG_FILENAME"
rm "$BLOG_FILENAME.tmp"
ls -lart
cat "$BLOG_FILENAME"
This script is responsible for cloning the website repo, writing the blog post to the correct directory. Once the blog post is setup, we need to download images for different screen sizes into the correct directory.
echo "Downloading images..."
IMAGE_DIR=/tmp/gh/website-v7/static/images/hero
declare -a IMAGE_URLS=("$PREVIEW_URL" "$DESKTOP_URL" "$TABLET_URL" "$MOBILE_URL" "$FALLBACK_URL")
declare -a IMAGE_LOCATIONS=("$IMAGE_DIR"/"$BLOG_TITLE".preview.jpg "$IMAGE_DIR"/"$BLOG_TITLE".desktop.jpg "$IMAGE_DIR"/"$BLOG_TITLE".tablet.jpg "$IMAGE_DIR"/"$BLOG_TITLE".mobile.jpg "$IMAGE_DIR"/"$BLOG_TITLE".fallback.jpg)
IMAGE_SIZE=5
for (( i=0; i<IMAGE_SIZE; i++ ));
do
echo "Downloading: ${IMAGE_URLS[$i]}"
curl -o "${IMAGE_LOCATIONS[$i]}" "${IMAGE_URLS[$i]}"
done
After the images are ready, it’s time to push to Github.
echo "Committing changes..."
git config user.email "some-email@gmail.com"
git config user.name "mohseenrm"
cd /tmp/gh/website-v7 || exit 127
git add .
git commit -m "Adding new blog post"
git push origin master
echo "Done! $BLOG_FILENAME published to master."
I have Hugo setup in a different repository that’s hosted on Github, so I would need to build the blog then transfer over the files to the new repo, to begin deploying it to the webs.
cd /tmp/gh || exit 127
echo "Cloning ${GITHUB_WEBSITE_REPOSITORY} repo..."
rm -rf mohseenrm.github.io
git clone "$CLONE_WEBSITE_REPO_URL"
echo "Cleaning up old assets..."
cd mohseenrm.github.io || exit 127
rm -rf about css authors fonts page js images scss post
rm index.xml index.html sitemap.xml
echo "Building website..."
cd /tmp/gh/website-v7 || exit 127
hugo --gc --minify --destination /tmp/gh/mohseenrm.github.io
echo "Copying assets..."
cp -r /tmp/gh/mohseenrm.github.io/public/* /tmp/gh/mohseenrm.github.io
rm -rf /tmp/gh/mohseenrm.github.io/public
echo "Committing changes..."
cd /tmp/gh/mohseenrm.github.io || exit 127
git add .
git config user.email "some-email@gmail.com"
git config user.name "mohseenrm"
git commit -m "Publishing new blog post"
git push origin master
Done! 🚀 Finally let’s send a notification email to let us know it was successful.
In order to pass data from BashOperator to a Python task, we would need to echo some sort of result.
BLOG_URL=("${BLOG_FILENAME%%.*}")
echo "https://mohseen.dev/post/${BLOG_URL}@${BLOG_TITLE}"
Great, lastly I used Sendgrid to send emails, but you can use any email provider you like.
It was pretty smooth sailing from here on out. Let’s fetch the needed ENV variables and send this sucker to the inbox.
@task(task_id="send_success_email")
def send_success_email(ti=None):
context = ti.xcom_pull(task_ids="publish_blog_post")
content = context.split("@")
assert len(content) == 2
url, title = content[0], content[1]
def capitalize_words(s):
return re.sub(r"\w+", lambda m: m.group(0).capitalize(), s)
title = capitalize_words(title).replace("-", " ")
message = Mail(
from_email="gpt-publisher@mohseen.dev",
to_emails=["some-email@gmail.com"],
)
message.dynamic_template_data = {
"title": title,
"blog_post_url": url,
}
message.template_id = Variable.get("SENDGRID_SUCCESS_TEMPLATE")
try:
sg = SendGridAPIClient(Variable.get("SENDGRID_API_KEY"))
response = sg.send(message)
code, body, headers = response.status_code, response.body, response.headers
print(f"Response code: {code}")
print(f"Response headers: {headers}")
print(f"Response body: {body}")
print("Success Message Sent!")
return str(response.status_code)
except Exception as e:
print("Error: {0}".format(e))
raise e
This is an ideal scenario where nothing ever goes wrong. Luckily for us, we can configure Airflow to trigger a different task if any of the previous task fails.
@task(task_id="send_failure_email", trigger_rule="one_failed")
def send_failure_email(ti=None):
message = Mail(
from_email="gpt-publisher@mohseen.dev",
to_emails=["some-email@gmail.com"],
)
message.template_id = Variable.get("SENDGRID_FAILURE_TEMPLATE")
try:
sg = SendGridAPIClient(Variable.get("SENDGRID_API_KEY"))
response = sg.send(message)
code, body, headers = response.status_code, response.body, response.headers
print(f"Response code: {code}")
print(f"Response headers: {headers}")
print(f"Response body: {body}")
print("Failure Message Sent!")
return str(response.status_code)
except Exception as e:
print("Error: {0}".format(e))
raise e
All that’s left is to define the fallback task in relation to the previous tasks, so that it can catch failures and send me a fun email.
send_failure_email >> end
# Setup fallback for failure
pick_topic >> [call_gpt, send_failure_email]
call_gpt >> [process_blog_post, send_failure_email]
process_blog_post >> [fetch_images, send_failure_email]
fetch_images >> [process_images, send_failure_email]
process_images >> [run, send_failure_email]
run >> [send_success_email, send_failure_email]
send_success_email >> end
Here’s a visual representation of the DAG we just defined.
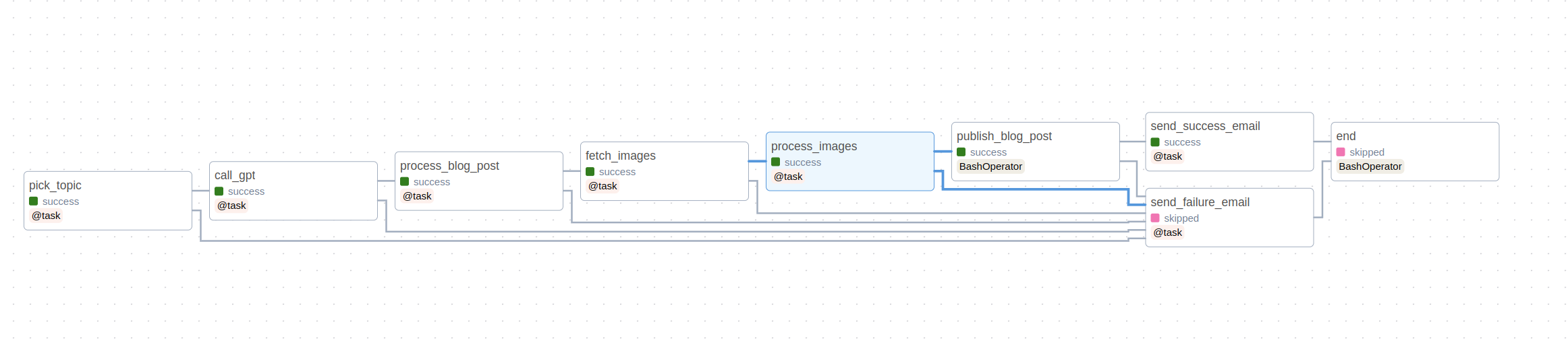
The key part of the fallback task is the trigger_rule. It only runs if any of the parent tasks fails. This is a great way to handle failures and send notifications to the relevant parties.
@task(task_id="send_failure_email", trigger_rule="one_failed")
Aiflow let’s you configure different rules for triggering tasks based on the state of the previous tasks. It’s pretty nifty and now my go-to anytime I need to automate something.
Once Airflow and GPT have done their magic, I get a nice email with the link to the blog post.

All I got to do is review it, make any changes and publish it. I can also trigger this manually from the UI if I’m feeling lucky.
Conclusion
This was a fun experiment, and I’m glad I got to learn a lot about Airflow and GPT-4. I’m sure there are a lot of ways to improve this, but for now I’m happily letting it crunch a few posts on my blog.
Stay synced.
Receive updates directly to your inbox. No noise, just data.
Image credits: Unsplash